
お久しぶりです
こんにちは。
筆跡鑑定チームです。
このチームはIchigoJamチームから派生したチームで、「筆跡鑑定によるユーザー認証」というテーマで研究を行っています。
筆跡鑑定によるユーザー認証
まず初めに、筆跡鑑定によるユーザー認証について説明します。
この研究は、パスワードや指紋などで行われるユーザー認証を、人工知能による筆跡鑑定に置き換えようというアイデアを基に研究を行っています。
筆跡鑑定に置き換えることによって、
- タッチパネルで認証を行えるため、高価なセンサーなどを用いずに、既存のデバイスで認証できる
- 手袋などをつけていても認証できる
- 偽造しにくい
などの利点があります。
この筆跡鑑定を、人工知能の技術で行うためにはどうすればいいかについて、現在研究を進めています。
目標
実現したときのイメージを説明します。
-
ユーザー登録:自分の名前の筆跡を10枚程度登録してもらう(これを本人かどうかの判断基準に使う)

-
認証:筆跡のみを要求→それをもとにどのユーザーか&本人かを判定する
ニューラルネットワークとは?
その前に・・・・・・
機械学習とは?
機械学習について説明します。
機械学習とは、経験からの学習により自動で改善するコンピューターアルゴリズムもしくはその研究領域(Wikipediaより)のことで、人工知能の一種です。
簡単に言うと、人間みたいに、見たり聞いたりしたものをもとに成長していく仕組みです。
訓練データと呼ばれるデータを読み込み学習し、それをもとに何かを判定したり動かしたりします。
勉強に例えると、
- とりあえず、わからないなりに教科書の問題(教師データ)を解いてみる
- 間違えたところを訂正する
- 1~3を繰り返す
- ある程度力がついてきたらテスト(テストデータ)で最終的な実力を測る
- 実際に学習内容を様々な場面で活用していく
みたいな具合です。
ニューラルネットワークとは?
機械学習のアルゴリズムの一つで、脳の神経伝達の仕組みを模したものです。
こちらのサイトに詳しい解説があります。
僕たちは、このニューラルネットワークというアルゴリズムを用いて、筆跡鑑定できないかと試行錯誤してきました。
シンプルなニューラルネットワーク
最初に僕たちが試した、シンプルなニューラルネットワークによる筆跡鑑定について説明します。
環境
- Ruby 2.7(プログラミング言語)
- scikit-learn 0.22(機械学習ライブラリ、機械学習の便利ツールの詰め合わせ)
- PyCall(scikit-learnをRubyから呼びだすためのライブラリ)
scikit-learnは本来、Pythonというプログラミング言語のためのライブラリで、Rubyで使うことはできません。
ですが、最終的にwebアプリにすることを考え、サーバーに強いRubyからPyCallを用いてscikit-learnを使うことにしました。
PyCallを用いた実装
PyCallを用いると、PythonのライブラリをRubyから呼び出して使うことができます。
PyCallの読み込み(Ruby)
require "pycall/import"
include PyCall::Import
※事前にRubyとPython、またPyCallと使いたいPythonのライブラリがインストールされている環境でないと動きません。
PyCallを読み込めば、pyimportやpyfromなどのメソッドが使えるようになり、Pythonのライブラリを読み込んで動かすことができるようになります。
Pythonのライブラリのチュートリアルやドキュメントのコードは、Pythonで書かれているためうまくRubyに書き換える必要があります。
ライブラリの読み込み(Python)
# scikit-learnの例
import sklearn.neural_network import MLPClassifier
# TensorFlowの例
from tensorflow import keras
from tensorflow.keras import datasets, layers, models
# そのほかのライブラリの例
import numpy as np
(Ruby)
# scikit-learnの例
pyimport "sklearn.neural_network", import: "MLPClassifier"
# Tensorflowの例
pyfrom "tensorflow", import: "keras"
pyfrom "tensorflow.keras", import: ["datasets", "layers", "models"] # 複数指定するときは配列を使う
# そのほかのライブラリの例
pyimport "numpy", as: "numpy"
# "文字列" の代わりに :シンボル を用いることもできる
pyfrom :tensorflow, import: :keras
# コンマが入る場合は "文字列" を使う、配列でも :シンボル を使える
pyfrom "tensorflow.keras", import: [:datasets, :layers, :models]
インスタンスを作る(Python)
# scikit-learnのニューラルネットワークの例
estimator = MLPClassifier(
solver="lbfgs",
activation="logistic",
alpha=1e-5,
hidden_layer_sizes=(5, 2),
random_state=1
)
(Ruby)
# scikit-learnのニューラルネットワークの例
estimator = MLPClassifier.new( # .newをつける
solver: "lbfgs", # =ではなく:を用いる
activation: :logistic, # :シンボル も使える
alpha: 1e-5, # 指数表現はそのままでも問題なし
hidden_layer_sizes: [5, 2], # タプル(配列のようなもの)は配列で表現
random_state: 1
)
関数を呼び出す(Python)
# scikit-learnの学習させる関数
estimator.fit(images, labels)
(Ruby)
# scikit-learnの学習させる関数
estimator.fit images, labels # 括弧はなくてもよい
テストの条件
-
筆跡データ
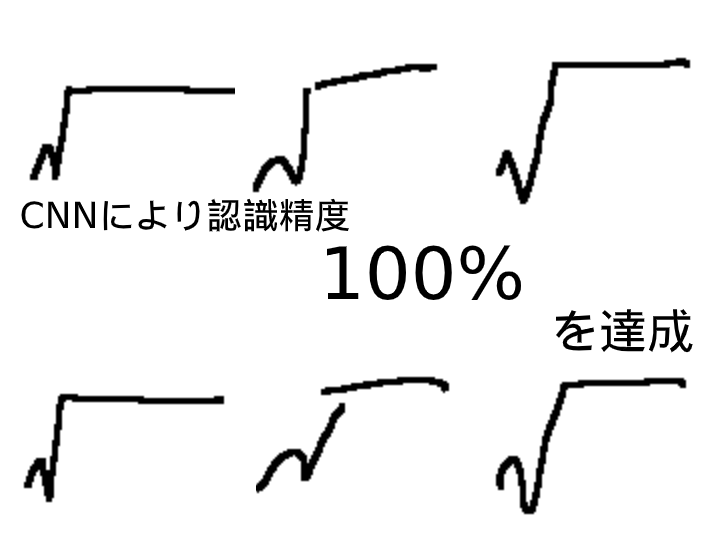
1人につき、教師データ:30枚、テストデータ:10枚の合計40枚の√記号を用いります。
これを2人分集めました。
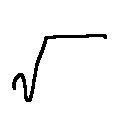
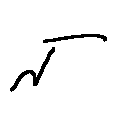
↑こんな感じ
人によって癖がかなりある√記号は、機械にとって認識しやすいためこの記号を用いりました。
今回はあくまでもテストなので、傾向などをつかむために良い結果が出やすいように機械に有利な条件で進めていきました。
-
検証方法
別の2人が書いた筆跡を、どちらが書いたものか分類する精度を測ります。
まず、教師データを分類器に学習させます。
教師データはどちらが書いたかのラベルが貼ってあり、分類器はどちらが書いたかを認識できます。
学習出来たら、テストデータで分類させて、どのくらい分類できるのかを検証します。
検証結果
いろいろなハイパーパラメータ(最初に設定しなければいけないパラメータ)を試したところ、最大で平均約80%の予測精度を達成しました。
ネットワークの設定
estimator = MLPClassifier.new(
hidden_layer_sizes: [64, 128],
activation: "tanh",
solver: "lbfgs",
max_iter: 100000,
tol: 0.0001
)
scikit-learnのパラメータですが、表記方法はRubyになっています。
畳み込みニューラルネットワーク(CNN)
ですが、80%の予測精度ではとても個人情報や金銭がかかっているユーザー認証で実用できる精度ではないので、画像認識に有利と言われている畳み込みニューラルネットワークを導入しました。
畳み込みニューラルネットワークは、ニューラルネットワークに人間の物体認識の仕組みのモデルを追加したもので、現在のAIブームの引き金となったものです。
これについてもこちらのサイトに詳しい解説があります。
環境
- Ruby 2.7(プログラミング言語)
- TensorFlow 2.4(機械学習ライブラリ)
- PyCall(scikit-learnをRubyから呼びだすためのライブラリ)
プログラミング言語は変わらないのですが、ライブラリをscikit-learnからTensorFlowに変更しました。
TensorFlowの方が、よりニューラルネットワーク向きで、ネットワークの層ごとに細かくいろいろなハイパーパラメータを設定出来るなどの利点があります。
その中でも、畳み込みニューラルネットワークを簡単に使うことができるのは大きな利点です。
検証結果
まず試しに、このチュートリアルをもとにCNNのネットワークを設定し、集めた筆跡データで認識するようにしたところ、いきなり100%の精度を出すことができました。
ネットワークの設定
model = models.Sequential.new([
layers.Conv2D.new(64, [5, 5], activation: :relu, input_shape: [128, 118, 1]),
layers.MaxPooling2D.new([4, 4]),
layers.Conv2D.new(64, [5, 5], activation: :relu),
layers.MaxPooling2D.new([4, 4]),
layers.Conv2D.new(32, [5, 5], activation: :relu),
layers.Flatten.new,
layers.Dense.new(128, activation: :relu),
layers.Dense.new(members.length, activation: :softmax)
])
もちろん、条件は先ほどのscikit-learnの時と変わりません。
教師データとテストデータを入れ替えたりして何度かやってみても、100%の結果が変わることはありませんでした。
さらには、2人の分類からもう1人分の筆跡を増やして、3人の分類に変更しても100%の結果が変わることはありませんでした。
このことから、CNNは画像認識においてかなり強力であることを実感しました。
今後の課題
今回、CNNを使うとかなり高い精度を実現することが可能だとわかりました。
ですが、まだまだハイパーパラメータはとりあえずでチュートリアルのものを使っているだけで、少ししか調整していません。
また、分類する人数は3人と、実用には及ばないレベルなのでもっと増やしても精度を保てることを確認しなければなりません。
人数を増やすと、認識精度以外にも処理速度などもかなり低下する恐れがあります。
計算速度と精度のバランスを、ハイパーパラメータで調整する必要が出てくるでしょう。
目標は10人の筆跡を100%に近い精度で分類できるようにすることです。
実際にユーザー認証システムを実装する場合は、名前でまず分類して、その中で誰の筆跡か分類することになるでしょう。
同姓同名の人は、平均約4人(このサイトより)とかなり少ないため、同じ文字列が記入されている筆跡を分類する場合は10人ほどを正確に分類できれば十分だろう考えたため、10人を目標にしました。
これを目標に、研究を頑張っていきます!
今後も、僕たちの応援よろしくお願いします!